Global protocols
Write the coordination once: messages, decisions, tools, LLM calls, and human approval points.
ZipperGen is a Python DSL and runtime for multi-agent LLM systems. You write one global protocol: who talks to whom, who calls tools or LLMs, and who owns each decision. ZipperGen projects the protocol to local agents and runs them concurrently.
Coordination is explicit, inspectable, and deadlock-free by construction.
Write the coordination once: messages, decisions, tools, LLM calls, and human approval points.
ZipperGen projects the protocol to one local program per lifeline. Each agent receives only the sends, receives, decisions, and actions it needs.
The projected agents run concurrently. The generated coordination code preserves the message structure of the protocol.
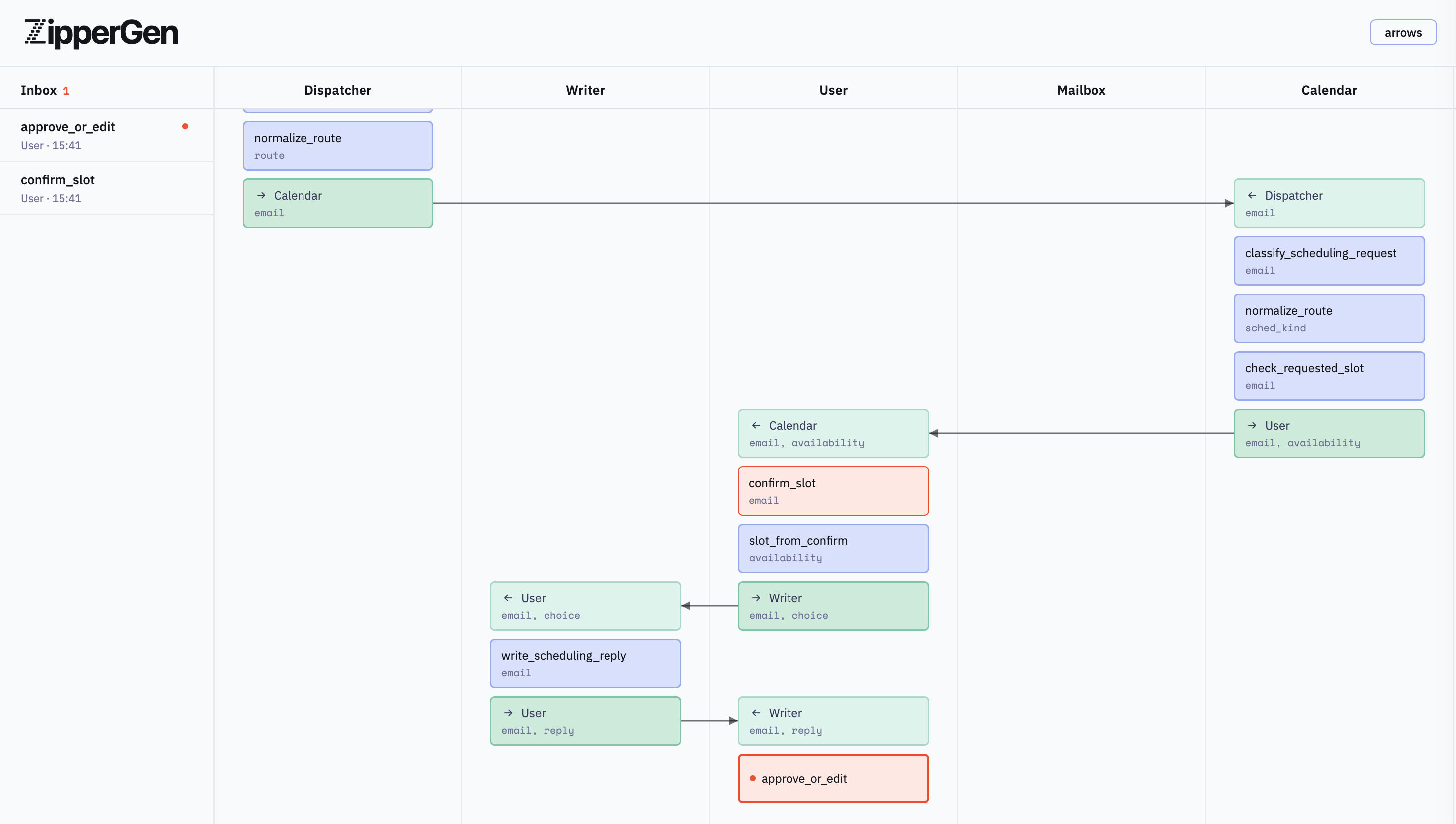
Runs can be inspected as message sequence charts in ZipperChat.
The projection is based on Message Sequence Charts and choreographic programming. The core deadlock-freedom theorem is machine-checked in Lean 4. The implementation is on GitHub.
Bollig, Függer, Nowak. Provable Coordination for LLM Agents via Message Sequence Charts. arXiv:2604.17612 [cs.PL]
Bollig. Causal Past Logic for Runtime Verification of Distributed LLM Agent Workflows. arXiv:2605.20923 [cs.LO]
Example: branching with an owner
The annotation @ Editor says that Editor owns the decision. ZipperGen
generates the control communication needed by the other lifelines.
@workflow
def write_tweet(topic: str @ User) -> str:
User(topic) >> Writer(topic)
Writer: tweet = draft(topic)
Writer(tweet) >> Editor(tweet)
Editor: approved = approve(tweet)
if approved @ Editor:
Editor(tweet) >> User(tweet)
else:
Editor(tweet) >> Writer(tweet)
Writer: tweet = revise(tweet)
Writer(tweet) >> User(tweet)
return tweet @ UserExample: command center
Calendar, Writer, and User are shared lifelines.
ZipperGen's projection ensures each receives exactly the messages it needs from
whichever branch generated them.
@workflow
def command_center():
with parallel:
with branch:
email_loop()
with branch:
chat_loop()Runtime guards
Guards can read the latest causally visible state instead of a sequential log. Vector clocks and message-carried views make the guard result depend on the asynchronous communication structure.
latest_device_on = At[Device].on == True
if latest_device_on @ Indicator:
...Run locally
The built-in mock backend returns placeholder model outputs. To use real model calls, set the provider to OpenAI, Mistral, or Claude with one configuration line. ZipperGen also accepts OpenAI-compatible local model servers such as vLLM.
git clone https://github.com/zippergen-io/zippergen.git
cd zippergen
pip install -e .
python examples/hello.py # two lifelines, one LLM call
python examples/command_center.py --mock # email triage + Telegram commands
python examples/parallel.py # fan-out / fan-in across branchesInspect the generated message sequence chart and decide whether global protocols fit your agent system.